Get Started Today
Want a free walkthrough of Airfinity’s products and solutions? Have a question about our disease outcome simulations? Perhaps you’d like to enquire about a custom analytics project? Fill out the form and tell us how we can help.
Disease-centric solutions combine proprietary surveillance tools and forecast models with expert analysis to produce actionable insights on disease outcomes, pipeline developments, standard of care, regulatory trends, future supply and demand, and more.
Our team of therapy-area specialists are on hand to respond to your query, understand your business challenges and learn how we can best support your organisation.
Get In Touch!
We’ll need a few short details about you and your business.
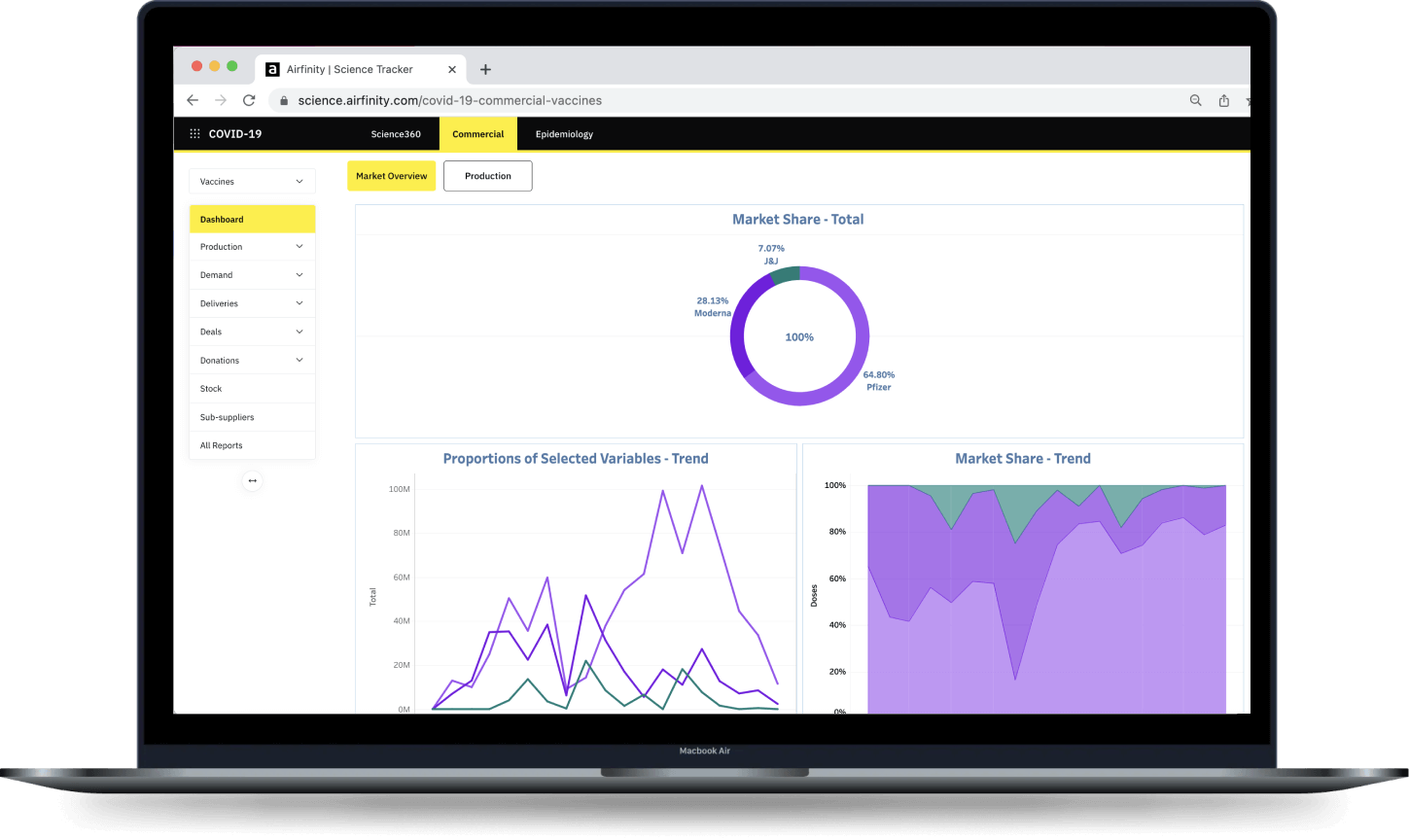
Our data
Broad and proprietary sources
Close to real-time with historical analogues
Dynamic scenario-based predictions
Bottom up forecasts built by therapy-area experts
Get In Touch!
We’ll need a few short details about you and your business.
What our users say?
“Airfinity has again and again shown they can provide very accurate and actionable predictions for disease trajectories. That’s why their analytics became an essential tool for me and the White House when leading outbreak responses such as COVID-19, mpox, Marburg Virus Disease and Avian Flu.”
Nikki Romanik, Former Special Assistant to the President, Deputy Director and Chief of Staff,
Office of Pandemic Preparedness and Response Policy, White House
In a dynamic environment, Airfinity enabled us to remain on track with daily developments to enable more accurate decision-making. Airfinity combines nimbleness of real time data and their group of scientists that can analyse, model and provide strategic analysis for critical decision making.”
Iskra Reic, Executive Vice-President
Astrazeneca

“The Airfinity report is a guide for world leaders to fix a more ambitious action plan.”
Gordon Brown, WHO Ambassador for Global Health Financing & former UK Prime Minister

“Airfinity has been instrumental in our country's COVID response.”
Head of UK Government
Vaccine Task Force
“Probably the most expansive, accurate and helpful of the multiple data sets on an international scale”
Sir John Bell ,
University of Oxford